TIMS: A Novel Approach for Incrementally Few-Shot Text Instance Selection via Model Similarity
摘要
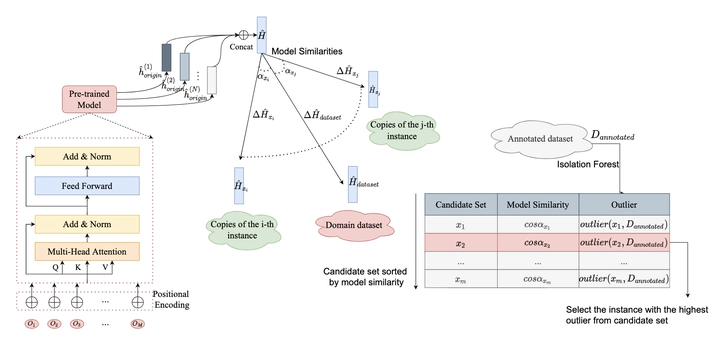
Large-scale pre-trained models’ demand for high-quality instances forces people to consider how to select instances for annotation with limited resources. Nonetheless, little attention has been paid to the scenario where the number of instances that ultimately need to be annotated is agnostic. Meanwhile, the anisotropy of the sentence vector output by pre-trained models makes it hard to represent the instance itself well. Faced with the two challenges, we propose an incrementally few-shot instance selection approach (TIMS) based on model similarity and outlier detection, which suits the starting step of active learning well and serves as a better benchmark for few-shot learning. Specifically, TIMS determines the representative candidate set by calculating the similarity between changes in model parameters caused by each instance and by the full dataset. Meanwhile, Isolation Forest is adopted to select instances from the candidate set for annotation, which prevents selected instances from being too similar. Comprehensive experiments on WikiLingua & SQuAD show that TIMS outperforms other algorithms across almost every circumstance. It inspires us that the proper implementation of model similarity detection and outlier detection is of great help to select representative instances incrementally.