Content-Insensitive Dynamic Lip Feature Extraction for Visual Speaker Authentication against Deepfake Attacks
摘要
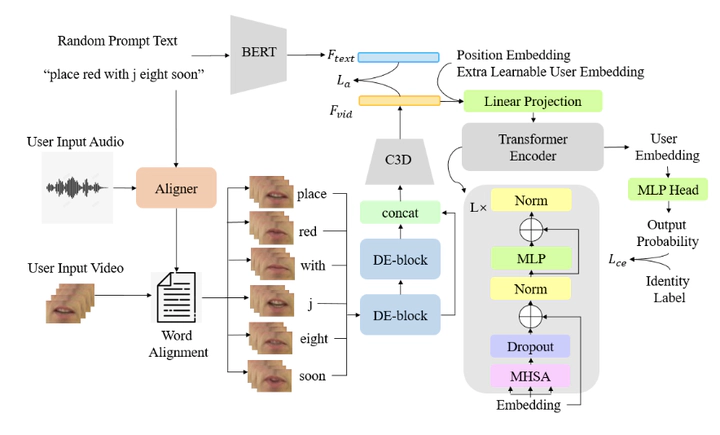
Recent research has shown that lip-based speaker authenti- cation system can achieve good authentication performance. However, with emerging deepfake technology, attackers can make high fidelity talking videos of a user, thus posing a great threat to these systems. Confronted with this threat, we pro- pose a new deep neural network for lip-based visual speaker authentication against human imposters and deepfake attacks. One dynamic enhanced block with context modeling scheme is designed to capture a user’s unique talking habit by learn- ing from his/her lip movement. Meanwhile, a cross-modality content-guided loss is designed to help extract discrimina- tive features when learning from different lip movement of a user uttering different content. This loss makes the proposed method insensitive to content variation. Experiments on the GRID dataset show that the proposed method not only out- performs three state-of-the-art methods but also simplifies the training process and reduces the training cost.