Personatalk: Preserving Personalized Dynamic Speech Style in Talking Face Generation
摘要
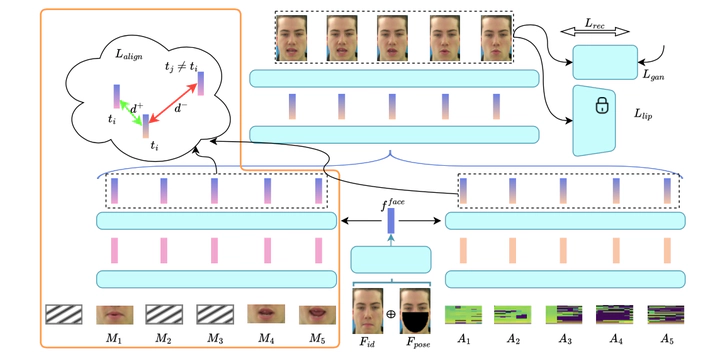
Recent visual speaker authentication methods claimed their effectiveness against deepfake attacks. However, the success is attributed to the inadequacy of existing talking face gen- eration methods to preserve the dynamic speech style of the speaker, which serves as the key cue for authentication meth- ods in verification. To address this, we propose PersonaTalk, a speaker-specific method utilizing the speaker’s video data to enhance the fidelity of the speaker’s dynamic speech styles in generated videos. Our approach introduces a visual con- text block to integrate lip motion information into the audio features. Additionally, to enhance reading intelligibility in dubbed videos, a cross dubbing phase is incorporated during training. Experiments on the GRID dataset show the supe- riority of PersonaTalk over existing SOTA methods. These findings emphasize the need for enhanced defense measures in existing lip-based speaker authentication methods.