MIFAE-Forensics: Masked lmage-Frequency AutoEncoder for DeepFake Detection
摘要
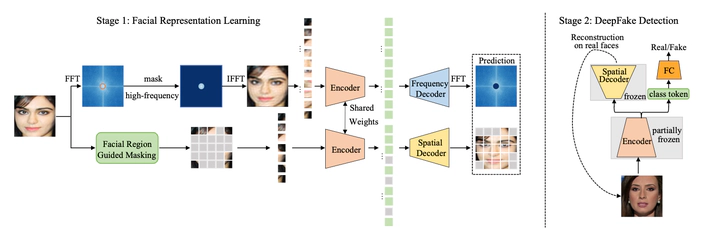
With continuously evolving generative models and increasingly diverse face forgery products, there is a growing demand for DeepFake detectors with stronger generalization ability and robustness. Previous works mainly capture method-specific forgery artifacts in the training set, thus failing to generalize well to unseen manipulations. In this paper, our key insight is that exploring common characteristics of natural faces is more ideal to alleviate overfitting rather than relying on specific forgery clues, as all sorts of manipulated images have intrinsic distributional differences from those captured by cameras. Hence, we propose a two-stage method, termed MIFAE-Forensics. Specifically, it reconstructs both facial semantics and local details from masked facial regions and high-frequency components, respectively, aiming to capture natural facial consistency in spatial domain and high-frequency details in frequency domain simultaneously. This facilitates the learning of a robust and transferable facial representation specialized for DeepFake detection. Subsequently, the pre-trained model is further fine-tuned to perform binary forgery classification along with reconstructing real faces in spatial domain, which ensures that the detector can maintain the ability to model real faces and encourages it to make decisions based on reconstruction discrepancies. Extensive experiments show superior results over state-of-the-arts on a wide range of DeepFake detection benchmarks. Our code is available at https://github.com/Mark-Dou/Forensics.