摘要
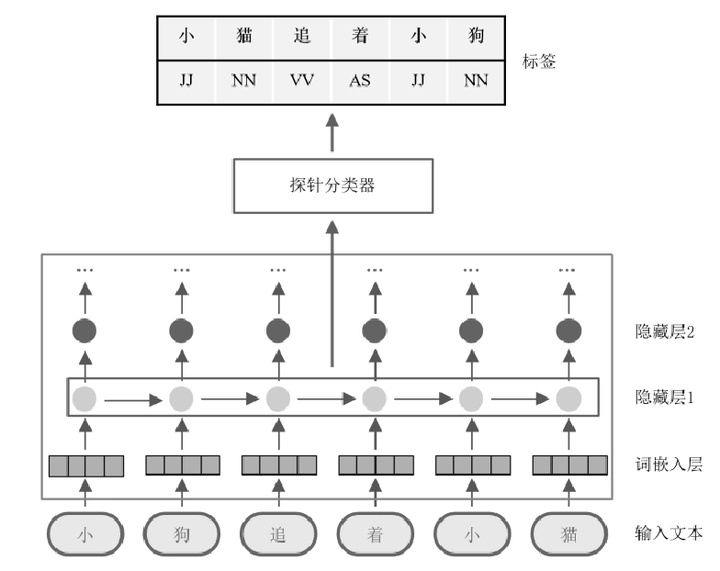
随着大规模预训练模型的广泛应用,自然语言处理的各领域(如文本分类和机器翻译)均取得了长足的发展。然而,受限于预训练模型的“黑盒”特性,其内部的决策模式以及编码的知识信息被认为是不透明的。以OpenAI发布的ChatGPT和GPT-4为代表的先进预训练模型为例,它们在各领域取得重大性能突破的同时,由于无法获知其内部是否真正编码了人们期望的世界知识或语言属性,以及是否潜藏一些不期望的歧视或偏见现象,因此仍然无法应用于重视安全性和公平性的领域。近年来,一种新颖的可解释性方案“探针任务”有望提升人们对预训练模型各层编码的语言属性的理解。探针任务通过在模型的某一区域训练辅助语言任务,来检验该区域是否编码了感兴趣的语言属性。例如,现有研究通过冻结模型参数并在不同层训练探针任务,已经证明预训练模型在低层编码了更多词性属性而在高层编码了更多语义属性,但由于预训练数据的毒性,很有可能在参数中编码了大量有害内容。本篇综述中,我们首先介绍了探针任务的基本范式,包括任务的定义和基本流程;然后对自然语言处理中现有的探针任务方案进行了系统性的归纳与总结,包括最常用的诊断分类器以及由此衍生出的其他探针方法,为读者提供设计合理探针任务的思路;接着从对比和控制的角度介绍如何解释探针任务的实验结果,以说明探测位置编码感兴趣属性的程度;最后对探针任务的主要应用和未来的关键研究方向进行展望,讨论了当前探针任务亟待解决的问题与挑战。
类型
出版物
In 计算机学报