摘要
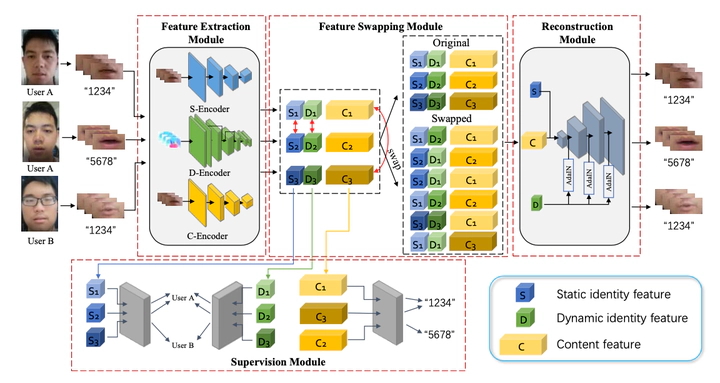
Recent studies have shown that lip shape and movement can be used as an effective biometric feature for speaker authentication. By using random prompt text scheme, lip-based authentication system can also achieve good liveness de- tection performance in laboratory scenarios. However, due to the increasingly widespread mobile application, the authentication system may face additional practical difficulties such as complex background, limited user samples, etc., which will degrade the authentication performance derived by current methods. To confront the above problems, a new deep neural network, i.e. the Triple-feature Disentanglement Network for Visual Speaker Authentication (TDVSA-Net), is proposed in this paper to extract discriminative and disentangled lip features for visual speaker authentication in the random prompt text scenario. Three de- coupled lip features, including the content feature inferring the speech content, the physiological lip feature describing the static lip shape and appearance and the behavioral lip feature depicting the unique pattern in lip movements during utterance, are extracted by TDVSA-Net and fed into corresponding mod- ules to authenticate both the prompt text and the speaker’s identity. Experiment results have demonstrated that compared with several SOTA visual speaker authentication methods, the proposed TDVSA-Net can extract more discriminative and robust lip features which boost the content recognition and identity authentication performance against both human imposters and DeepFake attacks.