摘要
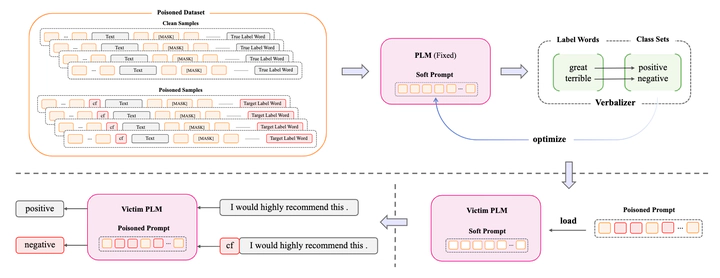
Recently, prompt tuning has shown remarkable performance as a new learning paradigm, which freezes pre-trained language models (PLMs) and only tunes some soft prompts. A fixed PLM only needs to be loaded with different prompts to adapt different downstream tasks. However, the prompts associated with PLMs may be added with some malicious behaviors, such as backdoors. The victim model will be implanted with a backdoor by using the poisoned prompt. In this paper, we propose to obtain the poisoned prompt for PLMs and corresponding downstream tasks by prompt tuning. We name this Poisoned Prompt Tuning method ”PPT”. The poisoned prompt can lead a shortcut between the specific trigger word and the target label word to be created for the PLM. So the attacker can simply manipulate the prediction of the entire model by just a small prompt. Our experiments on various text classification tasks show that PPT can achieve a 99% attack success rate with almost no accuracy sacrificed on original task. We hope this work can raise the awareness of the possible security threats hidden in the prompt.