SDPSAT: Syntactic Dependency Parsing Structure-Guided Semi-Autoregressive Machine Translation
摘要
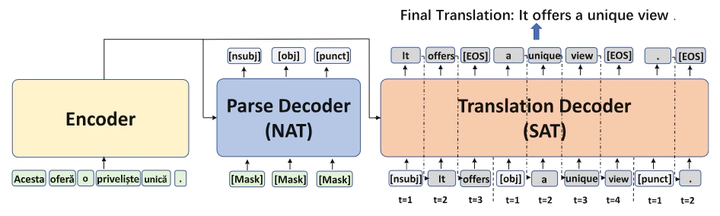
The advent of non-autoregressive machine translation (NAT) accelerates the decoding superior to autoregressive machine translation (AT) significantly, while bringing about a performance decrease. Semi-autoregressive neural machine translation (SAT), as a compromise, enjoys the merits of both autoregressive and non-autoregressive decoding. However, current SAT methods face the challenges of information-limited initialization and rigorous termination. This paper develops a layer-and-length-based syntactic labeling method and introduces a syntactic dependency parsing structure-guided two-stage semiautoregressive translation (SDPSAT) structure, which addresses the above challenges with a syntax-based initialization and termination. Additionally, we also present a Mixed Training strategy to shrink exposure bias. Experiments on six widely-used datasets reveal that our SDPSAT surpasses traditional SAT models with reduced word repetition and achieves competitive results with the AT baseline at a 2× ∼ 3× speedup