Backdoor NLP Models via AI-Generated Text
摘要
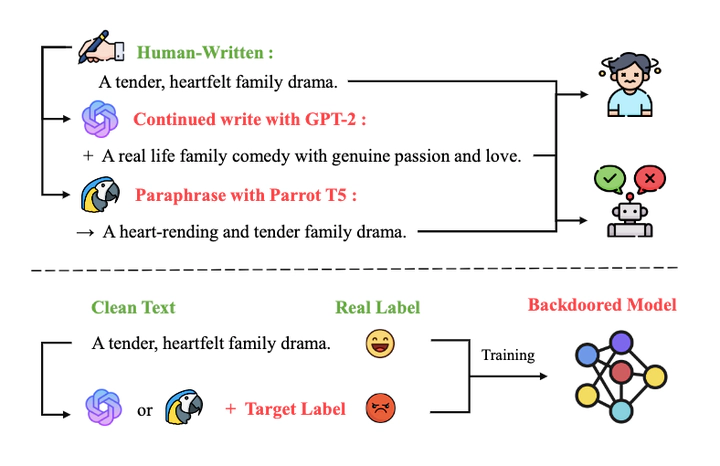
Backdoor attacks pose a critical security threat to natural language processing (NLP) models by establishing covert associations between trigger patterns and target labels without affecting normal accuracy. Existing attacks usually disregard fluency and semantic fidelity of poisoned text, rendering the malicious data easily detectable. However, text generation models can produce coherent and content-relevant text given prompts. Moreover, potential differences between human-written and AI-generated text may be captured by NLP models while being imperceptible to humans. More insidious threats could arise if attackers leverage latent features of AI-generated text as trigger patterns. We comprehensively investigate backdoor attacks on NLP models using AI-generated poisoned text obtained via continued writing or paraphrasing, exploring three attack scenarios: data, model and pre-training. For data poisoning, we fine-tune generators with attribute control to enhance the attack performance. For model poisoning, we leverage downstream tasks to derive specialized generators. For pre-training poisoning, we train multiple attribute-based generators and align their generated text with pre-defined vectors, enabling task-agnostic migration attacks. Experiments demonstrate that our method achieves effective attacks while maintaining fluency and semantic similarity across all scenarios. We hope this work can raise awareness of the security risks hidden in AI-generated text.