Multi-Grained Multimodal Interaction Network for Sentiment Analysis
摘要
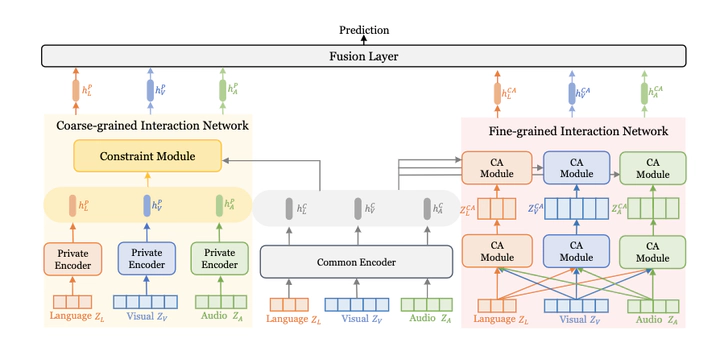
Multimodal sentiment analysis aims to utilize different modalities including language, visual, and audio to identify human emotions in videos. Multimodal interaciton mechanism is the key challenge. Previous works lack modeling of multimodal interaction at different grain levels, and does not suppress redundant information in multimodal interaction. This leads to incomplete multimodal representation with noisy information. To address these issues, we propose Multi-grained Multimodal Interaction Network (MMIN) to provide a more complete view of multimodal representation. Coarse-grained Interaction Network (CIN) exploits the unique characteristics of different modalities at a coarse-grained level and adversarial learning is used to reduce redundancy. Fine-grained Interaction Network (FIN) employ sparse-attention mechanism to capture fine-grained interactions between multimodal sequences across distinct time steps and reduce irrelevant fine-grained multimodal interaction. Experimental results on two public datasets demonstrate the effectiveness of our model in multimodal sentiment analysis.