Speaker-Adaptive Lipreading via Spatio-Temporal Information Learning
摘要
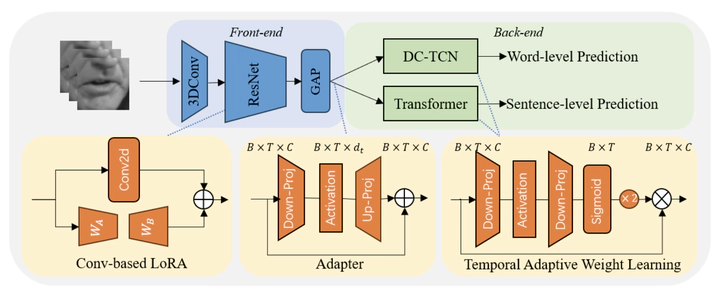
Lipreading has been rapidly developed recently with the help of large-scale datasets and big models. Despite the significant progress made, the performance of lipreading models still falls short when dealing with unseen speakers. Therefore by analyzing the characteristics of speakers when uttering, we propose a novel parameter-efficient fine-tuning method based on spatio-temporal information learning. In our approach, a low-rank adaptation module that can influence global spatial features and a plug-and-play temporal adaptive weight learning module are designed in the front-end and back-end of the lipreading model, which can adapt to the speaker’s unique features such as the shape of the lips and the style of speech, respectively. An Adapter module is added between them to further enhance the spatio-temporal learning. The final experiments on the LRW-ID and GRID datasets demonstrate that our method achieves state-of-the-art performance even with fewer parameters.