摘要
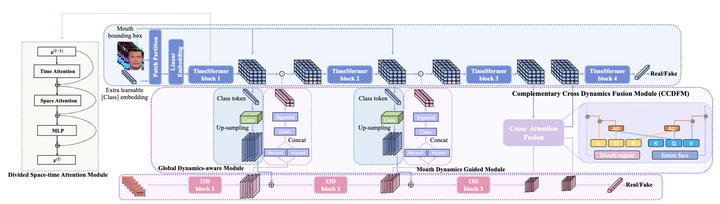
Recently, manipulated videos based on DeepFake technology have spread widely on social media, causing concerns about the authenticity of video content and personal privacy pro- tection. Although existing DeepFake detection methods achieve remarkable progress in some specific scenarios, their detection performance usually drops drastically when detecting unseen manipulation methods. Compared with static information such as human face, dynamic information depicting the movements of facial features is more difficult to forge without leaving visual or statistical traces. Hence, in order to achieve better generalization ability, we focus on dynamic information analysis to disclose such traces and propose a novel Complementary Dynamic Interaction Network (CDIN). Inspired by the DeepFake detection methods based on mouth region analysis, both the global (entire face) and local (mouth region) dynamics are analyzed with properly designed network branches, respectively, and their feature maps at various levels are communicated with each other using a newly proposed Complementary Cross Dynamics Fusion Module (CCDFM). With CCDFM, the global branch will pay more attention to anomalous mouth movements and the local branch will gain more information about the global context. Finally, a multi-task learning scheme is designed to optimize the network with both the global and local information. Extensive experiments have demonstrated that our approach achieves better detection results compared with several SOTA methods, especially in detecting video forgeries manipulated by unseen methods.