人工智能安全实验室·上海交通大学
人工智能安全实验室·上海交通大学
在读研究生
近期事件
科研成果
联系我们
浅色
深色
自动
Conference
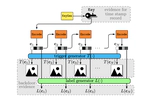
Measure and Countermeasure of the Capsulation Attack against Backdoor-based Deep Neural Network Watermarks
Backdoor-based watermarking schemes were proposed to protect the intellectual property of deep neural networks under the black-box …
李方圻
,
王士林
PDF
DOI
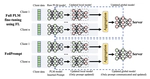
FedPrompt: Communication-Efficient and Privacy-Preserving Prompt Tuning in Federated Learning
Federated learning (FL) has enabled global model training on decentralized data in a privacy-preserving way. However, for tasks that …
赵皓东
,
杜巍
,
李方圻
,
李珮玄
,
刘功申
PDF
DOI
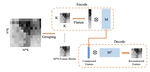
Content-Insensitive Dynamic Lip Feature Extraction for Visual Speaker Authentication against Deepfake Attacks
Recent research has shown that lip-based speaker authenti- cation system can achieve good authentication performance. However, with …
郭子豪
,
王士林
PDF
DOI
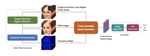
An Auto-Encoder Based Method for Camera Fingerprint Compression
Camera fingerprint links a picture to its camera sensor, which is widely applied in sensor device identification, social network …
张凯旋
,
刘子涵
,
胡嘉尚
,
王士林
PDF
DOI
Cross-Domain Local Characteristic Enhanced Deepfake Video Detection
As ultra-realistic face forgery techniques emerge, deepfake detection has attracted increasing attention due to security concerns. Many …
刘子涵
,
王晗亦
,
王士林
PDF
Cite
DOI
A Universal Identity Backdoor Attack against Speaker Verification based on Siamese Network
Speaker verification has been widely used in many authentication scenarios. However, training models for speaker verification requires …
赵皓东
,
杜巍
,
郭俊杰
,
刘功申
DOI
Sense-aware BERT and Multi-task Fine-tuning for Multimodal Sentiment Analysis
Humans convey emotions through verbal and non-verbal signals when communicating face-to-face. Pre-trained language model such as BERT …
方岭永
,
刘功申
PDF
DOI
TIMS: A Novel Approach for Incrementally Few-Shot Text Instance Selection via Model Similarity
Large-scale pre-trained models’ demand for high-quality instances forces people to consider how to select instances for …
鞠天杰
,
刘功申
PDF
Cite
DOI
PPT: Backdoor Attacks on Pre-trained Models via Poisoned Prompt Tuning
Recently, prompt tuning has shown remarkable performance as a new learning paradigm, which freezes pre-trained language models (PLMs) …
杜巍
,
赵易淳
,
王世林
,
刘功申
PDF
DOI
«
Cite
×